
En el intrincado universo de la búsqueda en línea, comprender cómo funciona Google es esencial para aquellos que buscan destacar en la era digital. En este artículo de agencia seo en México, nos sumergiremos en la dificultad de la búsqueda en Internet y en el mecanismo de clasificación de Google, según las valiosas perspectivas de Pandu Nayak, un destacado ingeniero de Google responsable de la calidad de la búsqueda y de la integridad del contenido.
Acompáñanos en un viaje a través de los algoritmos, las actualizaciones y los principios fundamentales que dan forma a la experiencia de búsqueda de millones de usuarios en todo el mundo. ¡Descubre los secretos detrás de las páginas de resultados y cómo puedes optimizar tu presencia en línea para destacar en este fascinante mundo de información digital!
Pandu Nayak testificó en el juicio antimonopolio entre Estados Unidos y Google en octubre. Todo lo que recordaba haber visto en ese momento era lo que parecía un artículo de relaciones públicas publicado por el New York Times .
Luego, AJ Kohn publicó Lo que Pandu Nayak enseñó sobre SEO el 16 de noviembre, que contenía un enlace a un PDF del testimonio de Nayak.
Indexación de google
Google rastrea la web y hace una copia de ella. Esto se llama índice.
Piense en un índice que pueda encontrar al final de un libro. Los sistemas tradicionales de recuperación de información (motores de búsqueda) funcionan de manera similar cuando buscan documentos web.
Pero la web está en constante cambio. El tamaño no lo es todo, explicó Nayak, y hay mucha duplicación en la web. El objetivo de Google es crear un “índice completo”. agencia seo en México.
En 2020, el índice era “quizás” de unos 400 mil millones de documentos, dijo Nayak. (Nos enteramos de que hubo un período de tiempo en el que ese número bajó, aunque no estaba claro exactamente cuándo).
- “No sé si en los últimos tres años ha habido un cambio específico en el tamaño del índice”.
- “Cuanto más grande no es necesariamente mejor, porque podrías llenarlo de basura”.
Puedes mantener el tamaño del índice igual si disminuyes la cantidad de basura que contiene”, dijo Nayak. “Eliminar información que no es buena” es una forma de “mejorar la calidad del índice”.
Nayak también explicó el papel del índice en la recuperación de información:
- “Entonces, cuando tenga una consulta, debe recuperar los documentos del índice que coincidan con la consulta. El núcleo de esto es el índice mismo. Recuerde, el índice es para cada palabra, cuáles son las páginas en las que aparece esa palabra. Y así, a esto se le llama índice invertido por varias razones. Y entonces, el núcleo del mecanismo de recuperación es mirar las palabras en la consulta, recorrer la lista (se llama lista de publicaciones) y cruzar la lista de publicaciones. Este es el mecanismo de recuperación central. Y como no puede recorrer las listas hasta el final porque serán demasiado largas, ordena el índice de tal manera que las páginas probablemente buenas, que son de alta calidad, por lo que a veces se ordenan por rango de página, por ejemplo, lo que se ha hecho en el pasado, es más o menos anterior. Y una vez que haya recuperado suficientes documentos para reducirlos a decenas de miles, esperará tener suficientes documentos. Entonces, este es el núcleo del mecanismo de recuperación: usar el índice para recorrer estas listas de publicaciones e intersecarlas para que se recuperen todas las palabras de la consulta”.
Clasificación de Google
Sabemos que Google usa el índice para recuperar páginas que coinciden con la consulta. ¿El problema? Millones de documentos podrían “coincidir” con muchas consultas de una agencia seo en México.
Es por eso que Google utiliza “cientos de algoritmos y modelos de aprendizaje automático, ninguno de los cuales depende totalmente de un modelo grande y singular”, según una publicación de blog que Nayak escribió en 2021.
Estos algoritmos y modelos de aprendizaje automático esencialmente “seleccionan” el índice de los documentos más relevantes, explicó Nayak.
- “Así que la siguiente fase es decir, está bien, ahora tengo decenas de miles. Ahora voy a utilizar un montón de señales para clasificarlas y obtener un conjunto más pequeño de varios cientos. Y luego puedo enviarlo a la siguiente fase de clasificación que, entre otras cosas, utiliza el aprendizaje automático”.
La guía de Google para los sistemas de clasificación de la Búsqueda de Google contiene muchos sistemas de clasificación con los que probablemente ya esté familiarizado (por ejemplo, BERT, sistema de contenido útil, PageRank, sistema de reseñas).
Pero Nayak (y otras pruebas del juicio antimonopolio) han revelado sistemas nuevos, previamente desconocidos, en los que podemos profundizar.
Señales de clasificación ‘Quizás más de 100’
Hace muchos años, Google solía decir que utilizaba más de 200 señales para clasificar las páginas. Ese número se disparó brevemente a 10.000 factores de clasificación en 2010 (Matt Cutts de Google explicó en un momento que muchas de las más de 200 señales de Google tenían más de 50 variaciones dentro de un solo factor), una estadística que la mayoría de agencia seo en México ha olvidado.
Bueno, ahora el número de señales de Google se ha reducido a “quizás más de cien”, según el testimonio de Nayak.
Lo que es “quizás” la señal más importante (que coincide con lo que dijo Gary Illyes de Google en Pubcon este año) para recuperar documentos es el documento en sí, dijo Nayak.
- “Todas nuestras señales principales de actualidad, nuestras señales de clasificación de páginas, nuestras señales de localización. Hay todo tipo de señales que analizan estas decenas de miles de documentos y juntas crean una puntuación que luego extrae los primeros cientos de allí”, dijo Nayak.
Las señales clave, según Nayak, son:
- El documento (también conocido como “las palabras en la página, etc.”).
- Actualidad.
- Calidad de la página.
- Fiabilidad.
- Localización.
- Impulso de navegación.
Aquí está la cita completa del juicio:
- “Quiero decir, en general, hay muchas señales. Ya sabes, tal vez más de cien señales. Pero para recuperar documentos, el documento en sí es quizás lo más importante, esas listas de publicaciones que tenemos y que utilizamos para recuperar documentos. Quizás eso sea lo más importante: reducirlo a decenas de miles. Y después de eso, nuevamente hay muchos factores. Hay una especie de código de tipo IR, algoritmos de tipo de recuperación de información que seleccionan la actualidad y cosas que son realmente importantes. Hay calidad de página. La confiabilidad de los resultados es otro factor importante. Hay cosas de tipo localización que suceden allí. Y eso también implica un impulso de navegación”.
Algoritmos centrales de Google
Google utiliza algoritmos centrales para reducir la cantidad de coincidencias de una consulta a “varios cientos” de documentos. Esos algoritmos centrales dan a los documentos clasificaciones o puntuaciones iniciales.
Cada página de agencia seo en México que coincide con una consulta obtiene una puntuación. Luego, Google clasifica las puntuaciones, que se utilizan en parte para presentarlas al usuario.
Los resultados web se califican mediante una puntuación IR (IR significa recuperación de información).
Navboost “es una de las señales importantes” que tiene Google, dijo Nayak. Este “sistema central” se centra en los resultados web y no lo encontrará en la guía de sistemas de clasificación de Google. También se le conoce como sistema de memorización.
El sistema Navboost se basa en los datos del usuario. Memoriza todos los clics en consultas de los últimos 13 meses. (Antes de 2017, Navboost memorizaba el historial de clics de los usuarios en consultas durante 18 meses).
El sistema se remonta al menos al año 2005, si no antes, dijo Nayak. Navboost se ha actualizado a lo largo de los años; ya no es el mismo que cuando se introdujo por primera vez.
- “Navboost está analizando muchos documentos y averiguando cosas al respecto. Así que es lo que selecciona entre muchos documentos y menos documentos”, dijo Nayak.
Tratando de no minimizar la importancia de Navboost, Nayak también dejó claro que Navboost es sólo una señal que utiliza Google. Se le preguntó a Nayak si Navboost es “el único algoritmo central que utiliza Google para recuperar resultados”, y dijo “no, absolutamente no”.
Navboost ayuda a reducir los documentos a un conjunto más pequeño para los sistemas de aprendizaje automático de Google, pero no puede ayudar a clasificar los “documentos que no tienen clics”. agencia seo en México.
Rebanadas de refuerzo de navegación
Navboost puede “dividir la información local” (es decir, la ubicación de origen de una consulta) y la información de datos que contiene por configuración regional.
Cuando se habla de “la primera selección” de “documentos locales” y la importancia de recuperar negocios que están cerca de la ubicación particular de un buscador (por ejemplo, Rochester, Nueva York), Google se los presenta al usuario “para que pueda interactuar con ellos y crear Navboost y demás”.
- “Recuerde, obtendrá Navboost sólo después de que se recuperen en primer lugar”, dijo Nayak.
Entonces, esto significa que Navboost es una señal de clasificación que solo puede existir después de que los usuarios hayan hecho clic en un documento/página.
Navboost también puede crear diferentes conjuntos de datos (porciones) para búsquedas en dispositivos móviles y en computadoras de escritorio. Para cada consulta, Google rastrea en qué tipo de dispositivo se fabrica. La ubicación importa si la búsqueda se realiza a través de una computadora de escritorio o un dispositivo móvil, y Google tiene un Navboost específico para dispositivos móviles.
- “Es una de las porciones”, dijo Nayak.
Pegamento
¿Qué es el pegamento?
“Glue es sólo otro nombre para Navboost que incluye todas las demás funciones de la página”, según Nayak, confirmando que Glue hace todo lo demás en el SERP de Google que no son resultados web.
El pegamento también se explicó en una exposición diferente ( Presentación del Prof. Douglas Oard , 15 de noviembre de 2023):
- “Glue agrega diversos tipos de interacciones del usuario, como clics, desplazamientos, desplazamientos y deslizamientos, y crea una métrica común para comparar resultados web y funciones de búsqueda. Este proceso determina si se activa una función de búsqueda y dónde se activa en la página”.
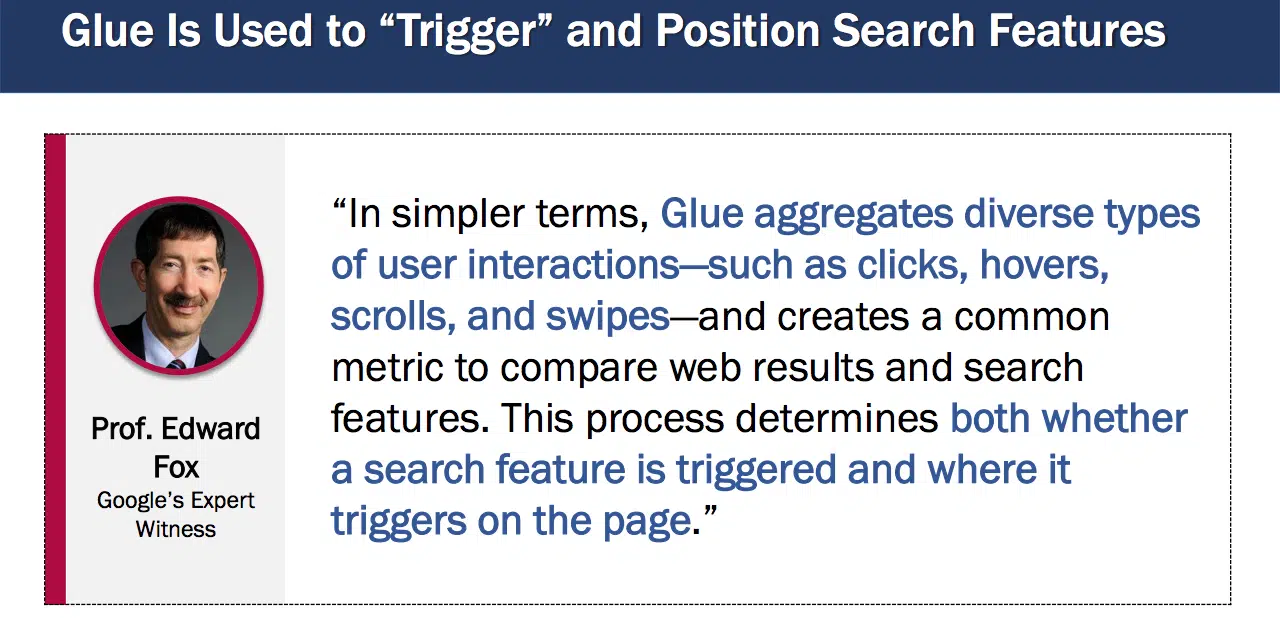
Además, a partir de 2016, Glue era importante para la clasificación de toda la página en Google:
- “Los datos de interacción del usuario de Glue ya se están utilizando en Web, KE [Knowledge Engine] y WebAnswers. Más recientemente, es una de las señales críticas del Tetris”.

También aprendimos sobre algo llamado Instant Glue, descrito en 2021 como una “canalización en tiempo real que agrega las mismas fracciones de señales de interacción del usuario que Glue, pero solo de las últimas 24 horas de registros, con una latencia de ~10 minutos”.

Navboost y Glue son dos señales que ayudan a Google a encontrar y clasificar lo que finalmente aparece en el SERP.
Sistemas de aprendizaje profundo
Google “comenzó a utilizar el aprendizaje profundo en 2015”, según Nayak (el año en que se lanzó RankBrain).
Una vez que Google tenga un conjunto más pequeño de documentos, el aprendizaje profundo se puede utilizar para ajustar las puntuaciones de los documentos.
Algunos sistemas de aprendizaje profundo también participan en el proceso de recuperación (por ejemplo, RankEmbed). La mayor parte del proceso de recuperación ocurre bajo el sistema central. agencia seo en México
¿Confiará alguna vez la Búsqueda de Google por completo en sus sistemas de aprendizaje profundo para la clasificación? Nayak dijo que no:
- “Creo que es arriesgado para Google, o para cualquier otra persona, entregar todo a un sistema como estos sistemas de aprendizaje profundo como una función de alto nivel de extremo a extremo. Creo que hace que sea muy difícil de controlar”.
Nayak analizó tres modelos principales de aprendizaje profundo que utiliza Google en la clasificación, así como cómo se utiliza MUM.
Rango Cerebro:
- Mira los 20 o 30 documentos principales y puede ajustar su puntuación inicial.
- Es un proceso más costoso que algunos de los otros componentes de clasificación de Google (es demasiado costoso ejecutarlo en cientos o miles de resultados).
- Está capacitado para realizar consultas en todos los idiomas y regiones en las que opera Google.
- Está ajustado a los datos de calificación IS ( Satisfacción de la información ).
- No se puede entrenar únicamente con datos de evaluadores humanos.
- RankBrain siempre se vuelve a capacitar con datos nuevos (durante años, RankBrain se capacitó con datos de consultas y clics de 13 meses).
- “RankBrain comprende las necesidades de los usuarios de cola larga mientras entrena…” dijo Nayak.
Rango profundo:
- Es BERT cuando se utiliza BERT para la clasificación.
- Está asumiendo más capacidades de RankBrain.
- Está capacitado sobre los datos del usuario.
- Está ajustado a los datos de calificación del IS.
- Entiende el lenguaje y tiene sentido común, según un documento leído a Nayak durante el juicio. Como se cita durante el testimonio de Nayak en un documento de DeepRank:
- “DeepRank no sólo proporciona importantes ganancias en relevancia, sino que también vincula más estrechamente la clasificación con el campo más amplio de la comprensión del lenguaje”.
- “Una clasificación eficaz parece requerir cierta comprensión del idioma junto con el mayor conocimiento posible del mundo”.
- “En general, la comprensión eficaz del lenguaje parece requerir una computación profunda y una cantidad modesta de datos”.
- “Por el contrario, el conocimiento mundial tiene que ver con datos; mientras más, mejor.”
- “DeepRank parece tener la capacidad de aprender la comprensión del lenguaje y el sentido común en el que se basan los evaluadores para estimar la relevancia, pero no la capacidad suficiente para aprender la gran cantidad de conocimiento mundial necesario para codificar completamente las preferencias del usuario”.
DeepRank necesita tanto comprensión del lenguaje como conocimiento del mundo para clasificar documentos, confirmó Nayak. (“La comprensión del lenguaje conduce a la clasificación. Por lo tanto, DeepRank también clasifica”). Sin embargo, indicó que DeepRank es una especie de “caja negra”:
- “Así que aprendió algo sobre la comprensión del lenguaje, y estoy seguro de que aprendió algo sobre el conocimiento del mundo, pero me resultaría difícil darles una declaración clara sobre esto. Estas son cosas como inferidas”, explicó Nayak.
¿Qué es exactamente el conocimiento mundial y de dónde lo obtiene DeepRank? Nayak explicó:
- “Una de las cosas interesantes es que se obtiene mucho conocimiento mundial de la web. Y hoy, con estos grandes modelos de lenguaje que se entrenan en la web (has visto ChatGPT, Bard, etc.), tienen mucho conocimiento mundial porque están entrenados en la web. Entonces necesitas esos datos. Conocen todo tipo de datos específicos al respecto. Pero necesitas algo como esto. En la búsqueda, puedes obtener conocimiento mundial porque tienes un índice y recuperas documentos, y esos documentos que recuperas te brindan conocimiento mundial sobre lo que está sucediendo. Pero el conocimiento del mundo es profundo, complicado y complejo, por lo que se necesita alguna forma de llegar a eso”.
Clasificación Incrustar BERT:
- Inicialmente se lanzó antes, sin BERT.
- Aumentado (y renombrado) para usar el algoritmo BERT “para que fuera aún mejor en la comprensión del lenguaje”.
- Está capacitado en documentos, clic y consulta de datos.
- Está ajustado a los datos de calificación del IS.
- Es necesario volver a capacitarlo para que los datos de entrenamiento reflejen eventos nuevos.
- Identifica documentos adicionales además de los identificados mediante la recuperación tradicional.
- Capacitado con una fracción de tráfico más pequeña que DeepRank: “tener cierta exposición a los datos nuevos es realmente bastante valioso”.
MUM:
MUM es otro modelo costoso de Google, por lo que no se ejecuta para todas las consultas en “tiempo de ejecución”, explicó Nayak:
- “Es demasiado grande y demasiado lento para eso. Entonces, lo que hacemos allí es entrenar otros modelos más pequeños usando el entrenamiento especial, como el clasificador del que hablamos, que es un modelo mucho más simple. Y ejecutamos esos modelos más simples en producción para atender los casos de uso”.
QBST y ponderación de términos
QBST (Términos destacados basados en consultas) y la ponderación de términos son otros dos “componentes de clasificación” sobre los que no se le preguntó a Nayak. Pero estos aparecieron en dos diapositivas de la exposición de Oard vinculadas anteriormente.

Estas dos integraciones de clasificación se basan en datos de calificación. QBST, al igual que Navboost, se conoce como un sistema de memorización (lo que significa que probablemente utiliza datos de consultas y clics). Más allá de su existencia, aprendimos poco sobre cómo funcionan.
El término “sistemas de memorización” también se menciona en un correo electrónico de Eric Lehman . Puede que sea simplemente otro término para los sistemas de aprendizaje profundo de Google:
- “Es posible que la relevancia en la búsqueda web no disminuya rápidamente en el aprendizaje automático profundo, porque dependemos de sistemas de memorización que son mucho más grandes que cualquier modelo de aprendizaje automático actual y capturan una gran cantidad de conocimientos aparentemente cruciales sobre el lenguaje y el mundo”.
Ensamblando el SERP
Las funciones de búsqueda son todos los demás elementos que aparecen en el SERP que no son los resultados web. Estos resultados también “obtienen una puntuación”. No quedó claro en el testimonio si se trata de una puntuación IR o de un tipo diferente de puntuación.
El sistema Tangram (anteriormente conocido como Tetris)
Aprendimos un poco sobre el sistema Tangram de Google, que antiguamente se llamaba Tetris.
El sistema Tangram agrega funciones de búsqueda que no se recuperan a través de la web, basándose en otras entradas y señales, dijo Nayak. El pegamento es una de esas señales.
Puede ver una descripción general de alto nivel de cómo funcionó Freshness en Tetris en 2018, en una diapositiva de la exhibición de prueba de Oard:
- Aplica pegamento instantáneo en Tetris.
- Degrada o suprime funciones obsoletas para consultas nuevas que lo merecen; promueve TopStories.
- Señales para consultas de noticias.

Evaluación de SERP y resultados de búsqueda
La puntuación IS es la principal métrica de nivel superior de calidad de búsqueda de Google. Esa puntuación se calcula a partir de las clasificaciones de los evaluadores de calidad de búsqueda. Es “una aproximación a la utilidad del usuario”.
IS es siempre una métrica humana. La puntuación proviene de 16.000 probadores humanos en todo el mundo.

“…Una cosa que Google podría hacer es buscar consultas en busca de inspiración sobre lo que podría necesitar mejorar. … Entonces creamos muestras de consultas que – en las cuales evaluamos qué tan bien lo estamos haciendo en general usando la métrica IS, y miramos – a menudo miramos consultas que tienen IS bajo para tratar de entender qué está pasando, qué estamos falta aquí… Así que esa es una forma de descubrir cómo podemos mejorar nuestros algoritmos”.
Nayak proporcionó algo de contexto para darle una idea de lo que es un punto de EI:

“Wikipedia es una fuente realmente importante en la web, con mucha información excelente. A la gente le gusta mucho. Si sacáramos Wikipedia de nuestro índice, completamente fuera de nuestro índice, eso conduciría a una pérdida de IS de aproximadamente medio punto. … Medio punto es una diferencia bastante significativa si representa toda la riqueza de información que Wikipedia contiene…”
IS, ranking y evaluadores de calidad de búsqueda
A veces, los documentos con puntuación IS se utilizan para entrenar los diferentes modelos en la pila de búsqueda de Google. Como se indica en la sección Clasificación, los datos del evaluador de IS ayudan a entrenar múltiples sistemas de aprendizaje profundo que utiliza Google.
Si bien es posible que usuarios específicos no estén satisfechos con la mejora de IS, “[en todo el corpus de usuarios de Google] parece que IS está bien correlacionado con la utilidad para los usuarios en general”, dijo Nayak.
Google puede utilizar evaluadores humanos para experimentar “rápidamente” con cualquier cambio en la clasificación, dijo Nayak en su testimonio.
- “Los cambios no lo cambian todo. Esa no sería una muy buena situación. Entonces, la mayoría de los cambios modifican algunos resultados. Tal vez cambien el orden de los resultados, en cuyo caso ni siquiera tienes que obtener nuevas calificaciones, o a veces agregan nuevos resultados y obtienes calificaciones para ellos. Por lo tanto, es una forma muy poderosa de poder iterar rápidamente cambios experimentales”.
Nayak también proporcionó más información sobre cómo los evaluadores asignan puntuaciones a los conjuntos de consultas:
- “Así que tenemos conjuntos de consultas creados de varias maneras como muestras de nuestro flujo de consultas donde tenemos resultados que han sido calificados por los evaluadores. Y utilizamos esto: estos conjuntos de consultas como una forma de experimentar rápidamente con cualquier cambio de clasificación”.
- “Digamos que tenemos un conjunto de consultas de, digamos, 15.000 consultas, está bien. Observamos todos los resultados de estas 15.000 consultas. Y nuestros evaluadores los califican”.
- “En general, estos se publican constantemente, por lo que los evaluadores ya han otorgado calificaciones para algunos de ellos. Podrías realizar un experimento que genere resultados adicionales y luego los calificarías”.
- “Muchos de los resultados que dan ya tenemos ratings del pasado. Y habrá algunos resultados sobre los que no tendrán calificaciones. Así que se los enviaremos a los evaluadores para que nos cuenten sobre esto. Ahora todos los resultados tienen calificaciones nuevamente, por lo que obtendremos una puntuación IS para el conjunto experimental”.
Otro descubrimiento interesante: Google decidió realizar todos los experimentos de evaluación con dispositivos móviles, según esta diapositiva:
Problemas con los evaluadores
Se pide a los evaluadores humanos que “se pongan en el lugar del usuario típico que podría estar allí”. Se supone que los evaluadores representan lo que busca un usuario general. Pero “cada usuario claramente tiene una intención, que sólo puedes adivinar”, dijo Nayak.
Los documentos de 2018 y 2021 destacan algunos problemas con los evaluadores humanos:
- Es posible que los evaluadores no comprendan las consultas técnicas.
- Los evaluadores no pueden juzgar con precisión la popularidad de nada.
- En IS Ratings, los evaluadores humanos no siempre prestan suficiente atención al aspecto de actualidad de la relevancia o carecen del contexto temporal para la consulta, lo que infravalora los resultados nuevos para consultas de búsqueda nueva.

Una diapositiva de una presentación ( Predicción unificada de clics ) indica que un millón de calificaciones IS son “más que suficientes para ajustar magníficamente las curvas a través de RankLab y el juicio humano”, pero brindan “sólo una imagen de baja resolución de cómo las personas interactúan con los resultados de búsqueda”.

Otras métricas de evaluación de la Búsqueda de Google
Una diapositiva de 2016 reveló que la calidad de la búsqueda de Google utiliza otras cuatro métricas principales para capturar la intención del usuario, además de IS:
- PQ (calidad de página)
- Lado a lado
- Experimentos en vivo
- Frescura

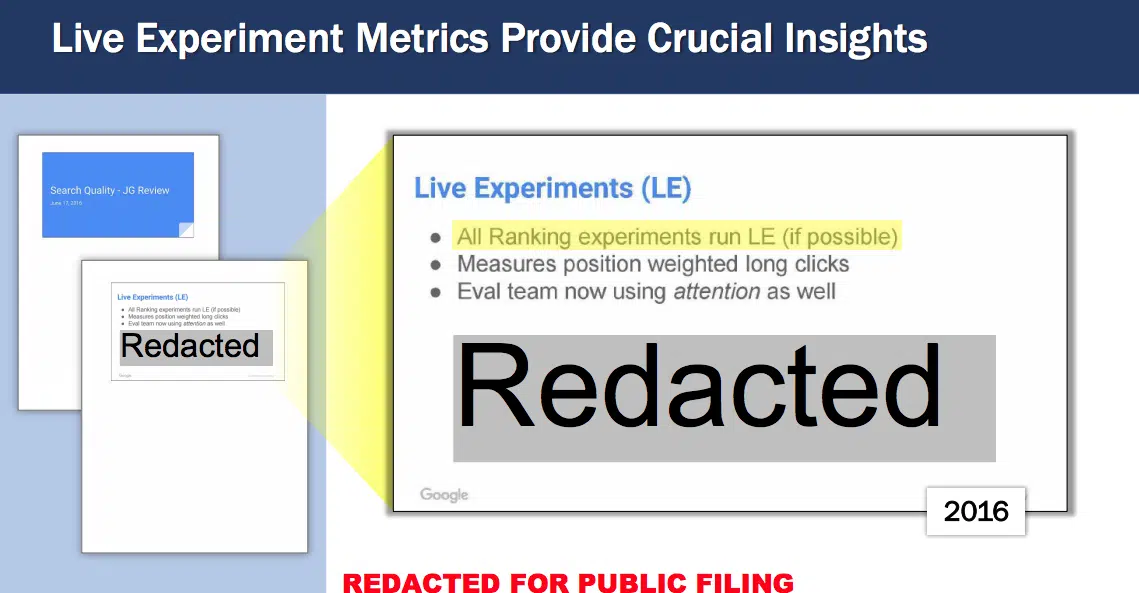
Sobre experimentos en vivo:
- Todos los experimentos de clasificación ejecutan LE (si es posible)
- Mide los clics largos ponderados por posición
- El equipo de evaluación ahora también usa la atención
Sobre la frescura:
“Un aspecto importante de la frescura es garantizar que nuestras señales de clasificación reflejen el estado actual del mundo”. (2021)
Todas estas métricas se utilizan para el desarrollo, lanzamiento y seguimiento de señales.
Aprendiendo de los usuarios
Entonces, si IS sólo proporciona una “imagen de baja resolución de cómo las personas interactúan con los resultados de búsqueda”, ¿qué proporciona una imagen más clara?
Clics.
No, no clics individuales. Estamos hablando de billones de ejemplos de clics, según la presentación Unified Click Prediction.

Como indica la diapositiva:
“~100.000.000.000 clics
Proporcionan una imagen mucho más clara de cómo las personas interactúan con los resultados de búsqueda.
Un patrón de comportamiento evidente en sólo unas pocas calificaciones de IS puede reflejarse en cientos de miles de clics, lo que nos permite conocer los efectos de segundo y tercer orden”.
Google ilustra un ejemplo con una diapositiva:

- Los datos de clics indican que los documentos cuyo título contiene dvm actualmente tienen una clasificación inferior para consultas que comienzan con [dr…]
- dvm = Doctor en Medicina Veterinaria
- Hay un par de ejemplos relevantes en el conjunto de 15K.
- Hay alrededor de un millón de ejemplos en datos de clics.
- Por lo tanto, el volumen de datos de clics para esta situación especial equivale aproximadamente al volumen total de todos los datos de calificación humana.
- Aprender esta asociación no solo es posible a partir de los datos de entrenamiento, sino que también es necesario para minimizar la función objetivo.
Clics en el ranking
Google parece equiparar el uso de clics con memorizar el material en lugar de comprenderlo. Por ejemplo, puedes leer un montón de artículos sobre SEO pero no entender realmente cómo hacer SEO. O cómo leer un libro de medicina no te convierte en médico.
Profundicemos en lo que la presentación de Predicción unificada de clics tiene que decir sobre los clics en la clasificación:

- La dependencia de los comentarios de los usuarios (“clics”) en la clasificación ha aumentado constantemente durante la última década.
- Mostrar resultados en los que los usuarios quieren hacer clic NO es el objetivo final del ranking web. Esto sería:
- Promocione resultados de baja calidad y de cebo de clics.
- Promocionar resultados con atractivo genuino que no sean relevantes.
- Sea demasiado indulgente con la opcionalización.
- Degradar páginas oficiales, promocionar pornografía, etc.
El objetivo de Google es descubrir en qué harán clic los usuarios. Pero, como muestra esta diapositiva, los clics son un objetivo indirecto:

- Pero mostrar resultados en los que los usuarios quieren hacer clic está CERCA de nuestro objetivo.
- Y podemos hacer esto “casi bien” extremadamente bien recurriendo a billones de ejemplos de comportamiento de los usuarios en los registros de búsqueda.
- Esto sugiere una estrategia para mejorar la calidad de la búsqueda:
- Predice en qué resultados harán clic los usuarios.
- Impulsa esos resultados.
- Solucionar problemas con la calidad de la página, relevancia, opcionalización, etc.
- No es una idea radical. Hemos hecho esto durante años.
Las siguientes tres diapositivas se sumergen en la predicción de clics, todas ellas tituladas “La vida dentro del Triángulo Rojo”. Esto es lo que nos dicen las diapositivas de Google:

- El “bucle interno” para las personas que trabajan en la predicción de clics se convierte en el ajuste de los datos de comentarios de los usuarios. La evaluación humana se utiliza en pruebas a nivel de sistema.
- Recibimos alrededor de 1.000.000.000 de nuevos ejemplos de comportamiento de usuario cada día, lo que permite una evaluación de alta precisión, incluso en lugares más pequeños. La prueba es:
¿Sus predicciones de clics fueron mejores o peores que la línea de base?
- Este es un objetivo totalmente cuantificable, a diferencia del problema más amplio de optimizar la calidad de la búsqueda. La necesidad de equilibrar múltiples métricas e intangibles se ve en gran medida impulsada hacia abajo.

- La metodología de evaluación es “entrenar en el pasado, predecir el futuro”. Esto elimina en gran medida los problemas de sobreajuste de los datos de entrenamiento.
- La evaluación continua se realiza en consultas nuevas y en el índice en vivo. Entonces, la importancia de la frescura está incorporada en la métrica.
- La importancia de la localización y una mayor personalización también están integradas en la métrica, para bien o para mal.

- Esta refactorización crea un problema de optimización monstruoso y fascinante: utilizar cientos de miles de millones de ejemplos de comportamiento pasado de usuario (y otras señales) para predecir el comportamiento futuro que involucra una amplia gama de temas.
- El problema parece demasiado grande para que lo asimile cualquier sistema de aprendizaje automático existente. Es probable que necesitemos alguna combinación de trabajo manual, ajuste de RankLab y aprendizaje automático a gran escala para lograr el máximo rendimiento.
- De hecho, la métrica cuantifica nuestra capacidad para emular a un buscador humano. Difícilmente se pueden evitar reflexiones sobre el Test de Turing y la Sala China de Searle.
- Pasar de miles de ejemplos de capacitación a miles de millones es algo que cambia las reglas del juego…
Comentarios de los usuarios (es decir, datos de clics)
Siempre que Google habla de recopilar datos de usuarios durante X meses, se refiere a todas “las consultas y los clics que se produjeron durante ese período de tiempo” de todos los usuarios, dijo Nayak.
Si Google estuviera lanzando sólo un modelo estadounidense, entrenaría su modelo en un subconjunto de usuarios estadounidenses, por ejemplo, dijo Nayak. Pero para un modelo global, analizará las consultas y los clics de todos los usuarios.
No todos los clics en la colección de registros de sesiones de Google tienen el mismo valor. Además, los datos más recientes de usuarios, clics y consultas no son mejores en todos los casos.
- “Depende de la consulta… hay situaciones en las que los datos más antiguos son en realidad más valiosos. Entonces creo que todas estas son preguntas empíricas para decir, bueno, qué está sucediendo exactamente. Claramente hay situaciones en las que los datos nuevos son mejores, pero también hay casos en los que los datos más antiguos son más valiosos”, dijo Nayak.
Anteriormente, Nayak dijo que hay un punto de rendimiento decreciente:
“…Y entonces existe esta compensación en términos de cantidad de datos que se utilizan, los rendimientos decrecientes de los datos y el costo de procesar los datos. Y por eso, normalmente hay un punto óptimo en el camino en el que el valor comienza a disminuir, los costos aumentan y ahí es donde hay que detenerse”.

El algoritmo de Priors
No, el algoritmo Priors no es una actualización de algoritmo, como contenido útil, spam o actualización principal. En estas dos diapositivas, Google destacó su visión del “problema de elección”.

“La idea es puntuar las puertas en función de cuánta gente las tomó.
En otras palabras, clasifica las opciones según su popularidad.
Esto es simple, pero muy poderoso. ¡Es una de las señales más fuertes para gran parte de la clasificación de anuncios y búsquedas de Google! Si no sabemos nada sobre el usuario, esto es probablemente lo mejor que podemos hacer”.
Google explica su “giro” personalizado (observando quién cruzó cada puerta y qué acciones las describen) en la siguiente diapositiva:

“Le damos dos vueltas de tuerca a la heurística tradicional.
En lugar de intentar describir, mediante un proceso ruidoso, de qué se trata cada puerta, la describimos basándonos en las personas que la tomaron.
Podemos hacer esto en Google, porque a nuestra escala, incluso la elección más oscura habría sido ejercida por miles de personas.
Cuando entra un nuevo usuario, medimos su similitud con las personas detrás de cada puerta.
Esto nos lleva al segundo giro, que es que al describir a un usuario, no [sic] utilizamos datos demográficos u otros atributos estereotipados.
Simplemente utilizamos las acciones pasadas de un usuario para describirlas y relacionarlas en función de su similitud de comportamiento”.
El ‘efecto red de datos’
Un dato final proviene del correo electrónico de Hal Varian que se publicó como prueba.
El Google que conocemos hoy es el resultado de una combinación de innumerables ajustes de algoritmos, millones de experimentos y aprendizajes invaluables a partir de datos de usuarios finales. O, como escribió Varian:
“Uno de los temas que surge constantemente es el ‘efecto red de datos’, que sostiene que
Alta calidad => más usuarios => más análisis => alta calidad
Aunque esto es más o menos correcto, 1) se aplica a todos los negocios, 2) el ‘más análisis’ debería ser realmente ‘más y mejor análisis’.
Gran parte de la mejora de Google a lo largo de los años se debe a que miles de personas… identificaron ajustes que han contribuido a que Google sea como es hoy.
Esto es demasiado sofisticado para que lo reconozcan periodistas y reguladores. Creen que si le entregáramos a Bing mil millones de consultas de cola larga, mágicamente mejorarían mucho”.







